5 minutes
Everything, All at Once: Cascading Failures

When we think of an outage, we usually think there is a single problem that needs to be fixed or worked around. This is usually the case, but sometimes that original single problem can cause other problems, a cascading failure.
Cascading Failures are more complicated to diagnose and resolve, often harder to find the true root cause. It also requires that you bring services back in the correct order or the dominos will fall again.
This post is an analysis of such a cascade failure in the lighting network of a multi venue theatre. We will look at what happened and the steps we took to bring things back to normal.
Background
The theatre has three venues. Each venue has a set of VLANs for lighting, however in this case we only need to look at the primary lighting VLAN for each venue. Each venue has a main switch in the main dimmer room, with additional switches in other locations around the venue. All the venues connect back to our core switch, creating a star of stars.
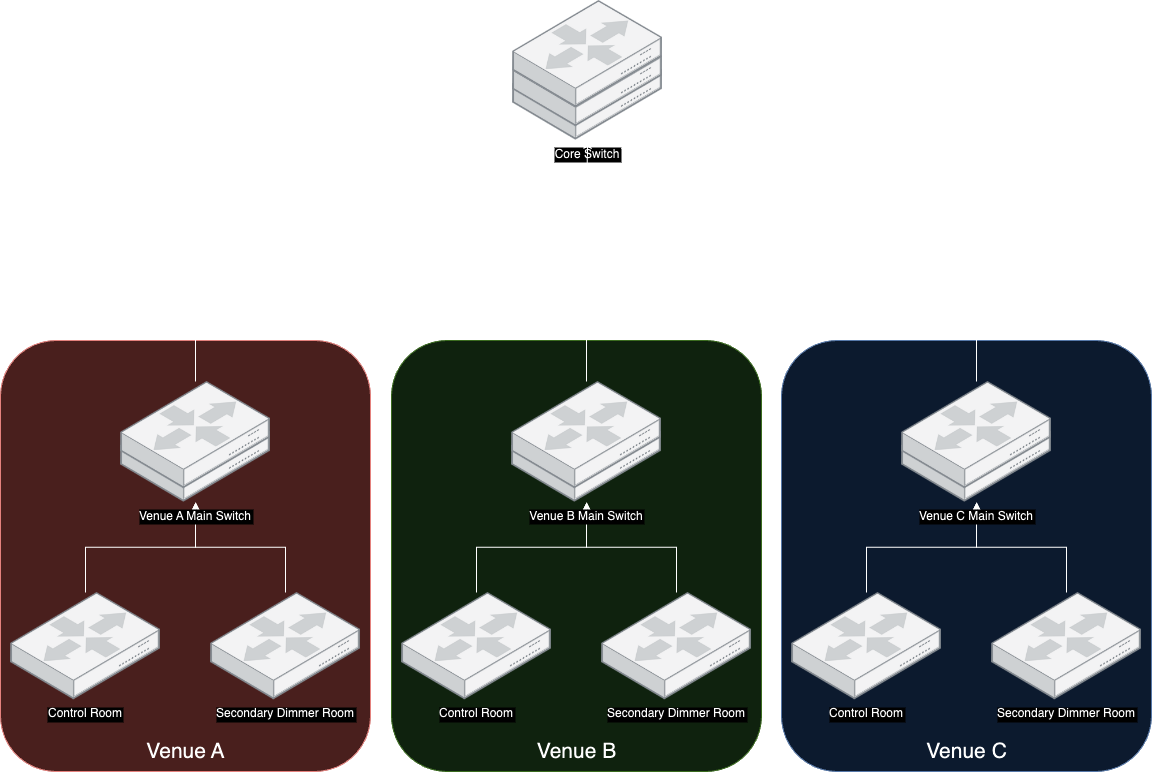
The Lighting VLAN for each venue is passed to:
- All the switches in it’s own venue
- The Core Switch
- The main switch in each venue
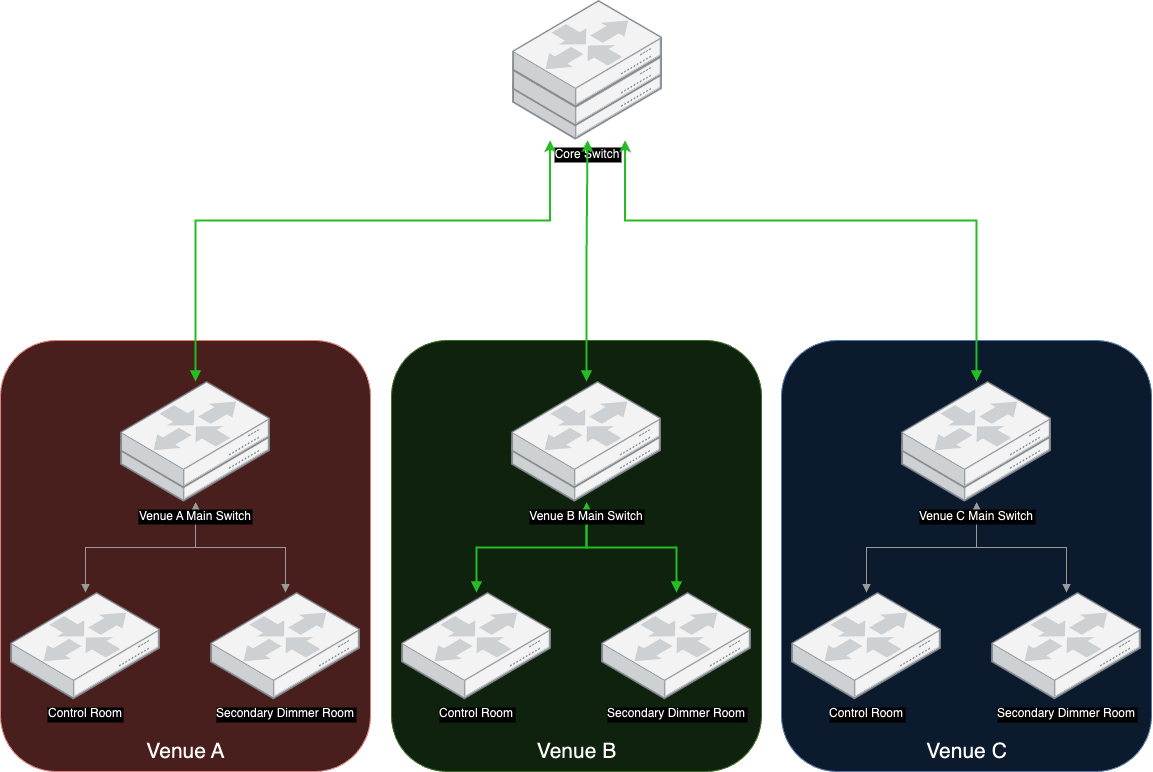
This allowed us to access other venues as needed, pass data between venues and helped simplify switch configuration. For example, the VLAN for Venue B is passed through all the green connections in the following diagram:
The Incident
Initial Report
I was contacted a little while after the incident began by the manager. At the time, I was in France attending PlugFest (An incredible event of interoperability between vendors in the industry) so received all the details from Teams Messages and Phone Calls.
Technicians returning at the half to open the house found that something had happened. The lighting desk’s had fallen out of sync, with the backups attempting to take control.
In Venue A & C, the technicians had no control of the rig. Everything was on and seemed to be running but they couldn’t actually control anything. Rebooting the desks failed to solve the issue.
In Venue B, the technicians had the messages that the backup had taken control, they were able to reboot and control everything as expected.
I was asked to begin remotely looking into the issues Venue A & C were experiencing while my manager made his way back to building.
Investigation
Logging in via our VPN, I began by looking through the logs of the main switch in Venue A. We had a lot of the usual messages, and one worrying one:
IGMP application is in Error State as System Resources are exhausted.
Traffic will flood.
For those that are less familiar with Lighting Control Protocols, we use one called sACN. This is the defacto for event lighting control, and allows the passage of DMX control data over an IP network. To accomplish this each universe of DMX (1 Universe is 512 slots of 8 bit data) is broadcast on a multicast address. Devices that need a specific universe can listen to that multicast address. To keep things efficient, IGMP is used so that multicast traffic is only sent to devices that need it.
Traffic flooding isn’t terrible. It’s not ideal, but the network should be able to take it for a night. But two venue’s have no control, so something isn’t right. Checking the control room switch, we found no such log message, meaning IGMP only crashed on the main dimmer room switch.
The Problem
With IGMP crashed on just the main switch, IGMP was running on the other switches but there was no querier to direct traffic. With no querier, traffic couldn’t pass anywhere.
Checking Venue B we found that IGMP had crashed on every switch. This explained why Venue B had control, none of the switches had IGMP running therefore the lighting control traffic for that venue was now in broadcast mode instead of IGMP mode.
Recovery
We rebooted the main switch in the venues that had no control. This restarted the IGMP application bringing control back. This did however take some time as spanning tree had to re-establish everything that was connected through the switch.
By this point, the decision to start the show in Venue B had been made as it was working and not experiencing any active issues. As such attempting to fix it’s IGMP application had to wait until the show had finished.
After the show’s had finished I rebooted every switch in Venue B, and double checked every switch in the other venues.
We also made the decision early on to disable out links with other departments. This was double sided:
- Protect us if the issue was coming from another depart
- Protect other departments if we have the same issue again
Root Cause
We started to try and track down the issue that caused IGMP to crash, however having rebooted most switches, and our switches clearing logs when rebooted, there was little information to go off of.
We did conduct some testing and found that it was likely due to a sudden influx of multicast traffic. Too much traffic, over around 2000 multicast groups, would casue the crash we saw. Doing this in one venue would cause the main switches in other venues to also crash, as we saw.
After several weeks of doing everything we could to trackdown the root cause, and slowly re-enabling links with other departments, we ran out of things to try. Unfortunatly to this day we haven’t been able to work out what caused the crash, just how the crash impacted our shows.
Things we learnt
In the month’s since the incident, we have put or started to put many things in place to help prevent these sorts of issues, the big higlights being:
- Build out a robust Syslog service so that logs are captured
- Add monitoring for the number of multicast groups on each vlan
- Obtain official support from our network hardware vendor (The vendor was extreemly helpful even without a support contract in place)
- Remove VLANs from venues that don’t need constant access to them